Introduction
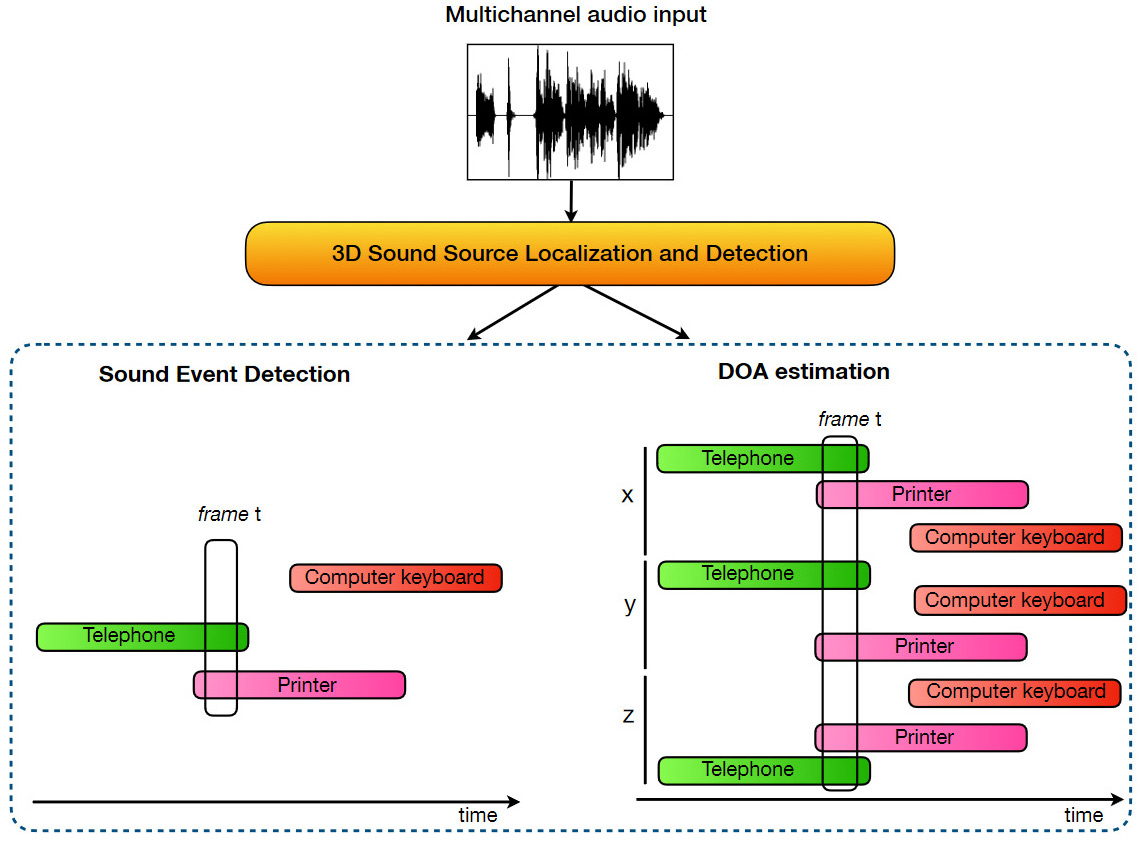
The aim of this task is to detect the temporal activity, spatial position and typology of a known set of sound events immersed in a synthetic 3D acoustic environment. We consider up to 3 simultaneously active sounds, which may belong to the same class. Here the models are expected to predict a list of the active sound events and their respective location at regular intervals of 100 milliseconds. We use a joint metric for localization and detection: F-score based on the Location-sensitive detection.
This metric considers a true positive only if a sound class is correctly predicted in a temporal frame and if it its predicted location lies within a fixed cartesian distance from the true position.
Sound event classes
To generate the spatial sound scenes the measured room IRs are convolved with clean sound samples belonging to distinct sound classes. The sound event database we used for task 2 is the well-known FSD50K dataset. In particular, we have selected 14 classes, representative of the sounds that can be heard in an office: computer keyboard, drawer open/close, cupboard open/close, finger snapping, keys jangling, knock, laughter, scissors, telephone, writing, chink and clink, printer, female speech, male speech.
Dataset specs
The main characteristics of the L3DAS22 SELD dataset are:
- 900 30-seconds-long data-points (a total of 7.5 hours)
- Sampling rate: 32 kHz 16 bit
- over 1000 sound event samples from FSD50K (14 sound classes)
- 252 RIRs positions collected in an office-like environment
- separate sets with 1, 2 or 3 overlaps