Introduction
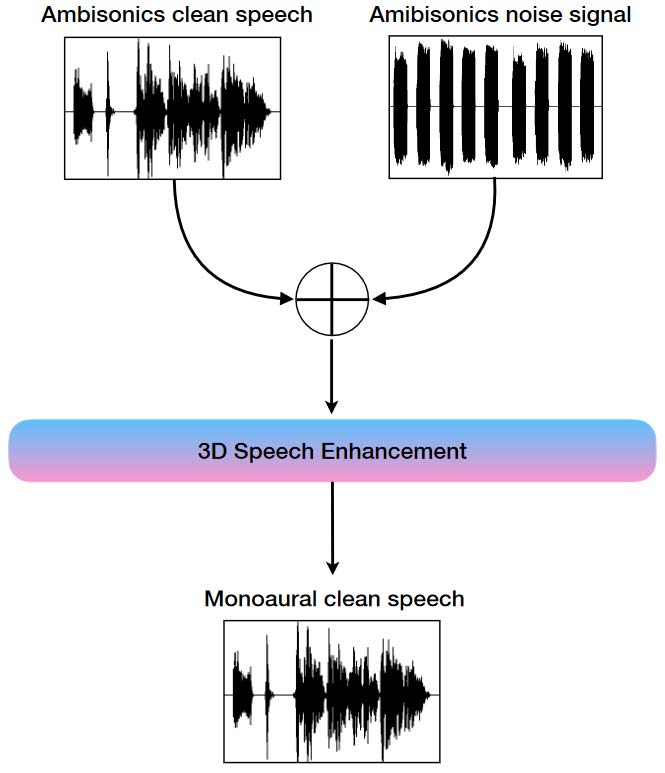
The objective of this task is the enhancement of speech signals immersed in a noisy 3D environment. Here the models are expected to extract the monophonic voice signal from the 3d mixture containing various background noises. Therefore, for this task we also provide the clean monophonic speech signal as target.
The evaluation metric for this task is a combination of the short-time objective intelligibility (STOI), which estimates the intelligibility of the output speech signal, and word error rate (WER), computed to assess the effects of the enhancement for speech recognition purposes. The final metric for this task is given by (STOI+(1−WER))/2, which lies in the 0-1 range and higher values are better.